
6月2日晚间,英伟达(NVIDIA)CEO黄仁勋在中国台湾大学综合体育馆发表主题为“开启产业革命的全新时代”的主题演讲。在长达两个小时的发言中,黄仁勋梳理并介绍了英伟达如何推动人工智能(AI)演进,以及AI如何变革工业。同时,他还宣布,Blackwell芯片现已开始投产,2025年将会推出Blackwell Ultra GPU芯片。下一代AI平台名为“Rubin”,将集成HBM4内存,将于2026年发布。
过去十年,计算成本降低了100万倍
计算机行业发展至今已有 60 年的历史。从IBM System 360 引入了中央处理单元、通用计算、通过操作系统实现硬件和软件的分离、多任务处理、IO子系统、DMA以及今天使用的各种技术。架构兼容性、向后兼容性、系列兼容性,所有今天对计算机了解的东西,大部分在1964 年就已经描述出来了。PC 革命使计算民主化,把它放在了每个人的手中和家中。
2007 年,iPhone 引入了移动计算,把计算机放进了我们的口袋。从那时起,一切都在连接并随时运行通过移动云。这 60 年来,我们只见证了两三次,确实不多,其实就两三次,主要的技术变革,计算的两三次构造转变,而我们即将再次见证这一切的发生,即GPU(图形处理器)所带来的加速计算。

黄仁勋表示,计算机行业在中央处理器(CPU)上运行的引擎,其性能扩展速度已经大大降低。但我们必须做的计算量,仍然在以指数级的速度增长,如果所需的性能没有如此增长,那么行业将经历计算的通货膨胀。和计算成本的提升。他指出,有一种更好的方法增强计算机的处理性能,减轻CPU的负担,那便是通过专用处理器,来实现了对于密集型应用程序的加速。
“现在,随着CPU扩展速度放缓,最终基本停止,我们应该加快让每一个处理密集型应用程序都得到加速,每个数据中心也肯定会得到加速,加速计算是非常明智的,这是很普通的常识。”黄仁勋表示。
他指出,计算机图形学是一门完全可以并行操作的学科。计算机图形学、图像处理、物理模拟、组合优化、图形处理、数据库处理,以及深度学习中非常 .的线性代数,许多类型的算法都非常适合通过并行处理来加速。

“通过结合GPU和CPU可以加速计算。我们可以让计算速度加快100倍,但功耗只增加了大约三倍,成本只增加了约 50%。”黄仁勋表示,英伟达在 PC 行业一直这样做,比如在1000 美元 PC 上加一个 500 美元 GeForce GPU,性能会大幅提升。在数据中心领域,英伟达也是这样做的,10亿美元的数据中心增加了5亿美元的GPU,它一下子变成了AI工厂。通过加速运算,还可以节省成本和能源。

黄仁勋指出,每一次加快应用程序的速度,计算成本就会下降,速度上升100倍,就可以节省96%、97%、98%的成本。在过去十年间,一种特定算法的边际计算成本降低了100万倍。“现在我们得以用互联网上所有数据来训练大语言模型。人工智能出现成为可能,是因为我们相信随着计算变得越来越 .,将会有人找到很好的用途。”
英伟达推动了大语言模型的诞生
黄仁勋强调,加速计算确实带来了非凡的成果,但它并不容易。原因是因为这非常难。没有一种软件可以通过C编译器运行,突然间应用程序就快了100倍。这甚至不合逻辑。如果可以做到这一点,他们早就改造 CPU了。因此,对于英伟达来说,必须重写软件,这是最难的部分。软件必须完全重写,以便能够重新表达在 CPU 上编写的算法,使其能够被加速、卸载并行运行。这种计算机科学的改变极其困难。
为了推动GPU所能够带来的计算加速,英伟达在2012年后改变了GPU的架构,采用Tensor Core(张量计算单元),并推出了一种协助“CPU任务分发+GPU并行处理”的编程模型/平台——CUDA,用于加速GPU和CPU之间的计算。 可以说,CUDA 增强了 CPU,卸载并加速了专用处理器可以更好完成的工作。
随后,黄仁勋花了较大篇幅来强调英伟达运算平台CUDA的重要性。黄仁勋表示,作为使用神经网络来进行深度学习的平台,CUDA显著推动了计算机科学在近20年内的进展。现在,全球已有500万名CUDA开发者。
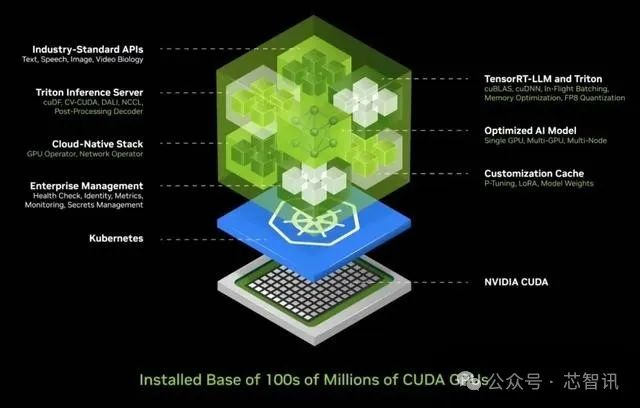
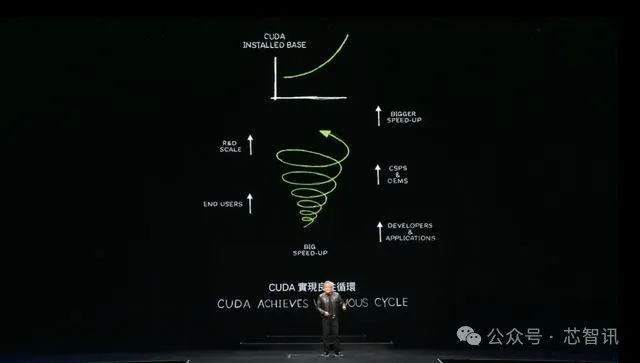
黄仁勋指出,CUDA已经实现了“良性循环”,能够在运算基础不断增长的情况下,扩大生态系统,令成本不断下降:“这将促使更多的开发人员提出更多的想法,带来更多的需求实验,成为伟大事业的开端。”
在CUDA之后,英伟达还发明了NVLink(一种总线及其通信协议),然后是TensorRT、NCCL,收购了Mellanox,推出TensorRT-ML、Triton推理服务器,所有这些都整合在一台全新的计算机上,助力了生成式AI的诞生。
“当时没人理解这件事(推出CUDA,并使得英伟达GPU支持CUDA),我也不认为会有人来买,当时我们在GTC大会上宣布了这件事,旧金山的一家小公司OpenAI看到了,他们便要我给他们送去一台。”黄仁勋表示,2016年,英伟达向OpenAI交付了 .台DGX超级计算机,随后继续扩展超级计算机的能力,以便训练大量数据。2022年11月,基于成千上万的英伟达GPU加速卡,OpenAI推出了ChatGPT,并在5天内收获了上百万名用户。
加速新的工业革命
黄仁勋表示,生成式人工智能的崛起,意味着我们可以学习并模拟物理现象,让人工智能模型理解并生成物理 .的各种现象。我们不再局限于缩小范围进行过滤,而是通过生成的方式探索无限可能。
如今,我们几乎可以为任何有价值的事物生成Token,无论是汽车的转向盘控制、机械臂的关节运动,还是我们目前能够学习的任何知识。因此,我们所处的已不仅仅是一个人工智能时代,而是一个生成式人工智能引领的新纪元。
更重要的是,英伟达最初作为超级计算机出现的设备,如今已经演化为一个高效运转的人工智能数据中心。它不断地产出,不仅生成Token,更是一个创造价值的人工智能工厂。这个人工智能工厂正在生成、创造和生产具有巨大市场潜力的新商品。
“正如19世纪末尼古拉·特斯拉(Nikola Tesla)发明了交流发电机,为我们带来了源源不断的电子,英伟达的人工智能生成器也正在源源不断地产生具有无限可能性的Token。这两者都有巨大的市场机会,有望在每个行业掀起变革。这确实是一场新的工业革命!”
黄仁勋兴奋的说道:“价值3万亿美元的IT行业,即将催生出能够直接服务于100万亿美元产业的创新成果。它不再仅仅是信息存储或数据处理的工具,而是每个行业生成智能的引擎。这将成为一种新型的制造业,但它并非传统的计算机制造业,而是利用计算机进行制造的全新模式。这样的变革以前从未发生过,这确实是一件令人瞩目的非凡之事。”
Blackwell已投产,2026年推出Rubin GPU
在今年3月的GTC2024大会,英伟达正式发布了面向下一代数据中心和人工智能应用的Blackwell GPU,时隔仅不到3个月,在此次的台大演讲当中,黄仁勋就披露了下一代的Blackwell Ultra GPU和再下一代的Rubin GPU。

据介绍,目前Blackwell芯片已经开始投产,它是当今 .上最复杂、性能最高的计算芯片。相比八年前的Pascal芯片,Blackwell芯片的AI算力提升了1000倍。

黄仁勋表示,英伟达在8年时间里,计算能力、浮点运算以及人工智能浮点运算能力增长了1000倍。这样的增长速度,几乎超越了摩尔定律在最佳时期的增长。
此外,相比八年前的Pascal芯片,Blackwell芯片用于训练GPT-4模型(2万亿参数和8万亿Token)训练的能耗下降了350倍。
黄仁勋解释称,如果使用Pascal进行同样的(GPT-4模型)训练,它将消耗高达1000吉瓦时的能量。这意味着需要一个吉瓦数据中心来支持,但 .上并不存在这样的数据中心。即便存在,它也需要连续运行一个月的时间。而如果是一个100兆瓦的数据中心,那么训练时间将长达一年。然而,利用Blackwell进行训练,则可以将原本需要高达1000吉瓦时的能量降低到仅需3吉瓦时,这一成就无疑是令人震惊的突破。想象一下,使用1000个GPU,它们所消耗的能量竟然只相当于一杯咖啡的热量。而10,000个GPU,更是只需短短10天左右的时间就能完成同等任务。
Blackwell不仅适用于推理,其在Token生成性能上的提升更是令人瞩目。在Pascal时代,生成每个Token消耗的能量高达17,000焦耳,这大约相当于两个灯泡运行两天的能量。而生成一个GPT-4的Token,几乎需要两个200瓦特的灯泡持续运行两天。考虑到生成一个单词大约需要3个Token,这确实是一个巨大的能量消耗。
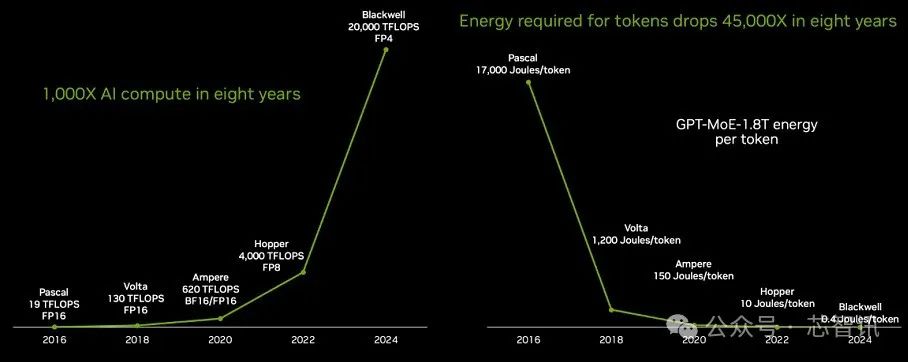
现在的情况已经截然不同,Blackwell的推出使得生成每个Token只需消耗0.4焦耳的能量,以惊人的速度和极低的能耗进行Token生成。相比Pascal的Token生成能耗降低了约350倍,这无疑是一个巨大的飞跃。

但即使如此,英伟达仍不满足,为了更大的突破,在推出整合Blackwell芯片的DGX系统的同时,英伟达还在持续研发新一代的GPU。
黄仁勋透露,英伟达将会在2025年推出增强版的Blackwell Ultra GPU(8S HBM3e 12H)。在2026年,英伟达还将推出再下一代的Rubin GPU,将集成8颗HBM4,随后在2027年,将推出Rubin Ultra GPU,将集成12颗HBM4版本。

根据外媒wccftech介绍,Rubin GPU将采用4x光罩设计,并将使用台积电3nm制程,以及CoWoS-L封装技术。
“在此展示的所有的新的芯片都处于 .开发阶段,确保每一个细节都经过精心打磨。我们的更新节奏依然是一年一次,始终追求技术的 .,同时确保所有产品都保持100%的架构兼容性。”黄仁勋说道。
生成式AI加速以太网
但对于新的基于AI的工业革命来说,光有AI算力的提升这还不足以满足需求,特别是对于大型人工智能工厂来说更是如此,因此还必须使用高速网络将这些人工智能工厂连接起来。
对此,英伟达推出了两种网络选择:InfiniBand和以太网。其中,InfiniBand已经在全球各地的超级计算和人工智能工厂中广泛使用,并且增长迅速。然而,并非每个数据中心都能直接使用InfiniBand,因为很多企业在以太网生态系统上进行了大量投资,而且管理InfiniBand交换机和网络确实需要一定的专业知识和技术。
因此,英伟达的解决方案是将InfiniBand的性能带到以太网架构中,这并非易事。原因在于,每个节点、每台计算机通常与互联网上的不同用户相连,但大多数通信实际上发生在数据中心内部,即数据中心与互联网另一端用户之间的数据传输。然而,在人工智能工厂的深度学习场景下,GPU并不是与互联网上的用户进行通信,而是彼此之间进行频繁的、密集的数据交换。
它们相互通信是因为它们都在收集部分结果。然后它们必须将这些部分结果进行规约(reduce)并重新分配(redistribute)。
这种通信模式的特点是高度突发性的流量。重要的不是平均吞吐量,而是最后一个到达的数据,因为如果你正在从所有人那里收集部分结果,并且我试图接收你所有的部分结果,如果最后一个数据包晚到了,那么整个操作就会延迟。对于人工智能工厂而言,延迟是一个至关重要的问题。
所以,英伟达关注的焦点并非平均吞吐量,而是确保最后一个数据包能够准时、无误地抵达。然而,传统的以太网并未针对这种高度同步化、低延迟的需求进行优化。为了满足这一需求,我们创造性地设计了一个端到端的架构,使NIC(网络接口卡)和交换机能够通信。
为了实现这一目标,英伟达采用了四种关键技术:
.,英伟达拥有业界 .的RDMA(远程直接内存访问)技术。现在,我们有了以太网网络级别的RDMA,它的表现非常 .;
第二,引入了拥塞控制机制。交换机具备实时遥测功能,能够迅速识别并响应网络中的拥塞情况。当GPU或NIC发送的数据量过大时,交换机会立即发出信号,告知它们减缓发送速率,从而有效避免网络热点的产生。
第三,采用了自适应路由技术。传统以太网按固定顺序传输数据,但在英伟达的架构中,其能够根据实时网络状况进行灵活调整。当发现拥塞或某些端口空闲时,可以将数据包发送到这些空闲端口,再由另一端的Bluefield设备重新排序,确保数据按正确顺序返回。这种自适应路由技术极大地提高了网络的灵活性和效率。
第四,实施了噪声隔离技术。在数据中心中,多个模型同时训练产生的噪声和流量可能会相互干扰,并导致抖动。英伟达的噪声隔离技术能够有效地隔离这些噪声,确保关键数据包的传输不受影响。
通过采用这些技术,英伟达成功地为人工智能工厂提供了高性能、低延迟的网络解决方案。在价值高达数十亿美元的数据中心中,如果网络利用率提升40%而训练时间缩短20%,这实际上意味着价值50亿美元的数据中心在性能上等同于一个60亿美元的数据中心,揭示了网络性能对整体成本效益的显著影响。
幸运的是,带有Spectrum X的以太网技术正是英伟达实现这一目标的关键,它大大提高了网络性能,使得网络成本相对于整个数据中心而言几乎可以忽略不计。这无疑是英伟达在网络技术领域取得的一大成就。
目前英伟达已经拥有一系列强大的以太网产品线,其中最引人注目的是Spectrum X800。这款设备以每秒51.2 TB的速度和256路径(radix)的支持能力,为成千上万的GPU提供了高效的网络连接。接下来,我们计划一年后推出X800 Ultra,它将支持高达512路径的512 radix,进一步提升了网络容量和性能。而X 1600则是为更大规模的数据中心设计的,能够满足数百万个GPU的通信需求。

黄仁勋强调,随着技术的不断进步,数百万个GPU的数据中心时代已经指日可待。这一趋势的背后有着深刻的原因。一方面,我们渴望训练更大、更复杂的模型;但更重要的是,未来的互联网和计算机交互将越来越多地依赖于云端的生成式人工智能。这些人工智能将与我们一起工作、互动,生成视频、图像、文本甚至数字人。因此,我们与计算机的每一次交互几乎都离不开生成式人工智能的参与。并且总是有一个生成式人工智能与之相连,其中一些在本地运行,一些在你的设备上运行,很多可能在云端运行。这些生成式人工智能不仅具备强大的推理能力,还能对答案进行迭代优化,以提高答案的质量。这意味着我们未来将产生海量的数据生成需求。
英伟达还宣布,包括华硕、技嘉、鸿佰科技、英业达、和硕、云达科技、美超威、纬创及纬颖、永擎电子等将利用英伟达的GPU与网络技术,推出云端、本地端、嵌入式与边缘AI系统。
AI机器人时代已经到来
展望未来,机器人技术将不再是一个遥不可及的概念,而是日益融入我们的日常生活。当提及机器人技术时,人们往往会联想到人形机器人,但实际上,它的应用远不止于此。机械化将成为常态,工厂将 .实现自动化,机器人将协同工作,制造出一系列机械化产品。它们之间的互动将更加密切,共同创造出一个高度自动化的生产环境。
黄仁勋指出:“结合AI的机器人时代已经到来。有朝一日,移动的物体都将实现自主运行。我们正致力于通过推进英伟达机器人堆栈的发展,来加速生成式物理AI,其中包括用于仿真应用的 Omniverse、Project GR00T人形机器人基础模型,以及Jetson Thor机器人计算平台等。”
基于此,英伟达宣布,比亚迪电子、西门子、泰瑞达和 Alphabet 旗下公司Intrinsic等全球十多家机器人企业,正在采用英伟达的机器人平台NVIDIA Isaac研究、开发和生产下一代 AI 赋能的自主机器和机器人,以此提高工厂、仓库和配送中心的工作效率,使机器人的人类同事更安全地工作,并使机器人成为执行重复性或超精密任务的智能助手。
未来,工厂内的机器人将成为主流,它们将制造所有的产品,其中两个高产量机器人产品尤为引人注目:一个是自动驾驶汽车或具备高度自主能力的汽车;另一个则可能是由机器人工厂高产量制造的产品是人形机器人。

在自动驾驶汽车方面,英伟达宣布,明年计划计划与梅赛德斯-奔驰车队携手,随后在2026年与捷豹路虎(JLR)车队合作。英伟达提供完整的解决方案堆栈,但客户可根据需求选择其中的任何部分或层级,因为整个驱动堆栈都是开放和灵活的。
在人形机器人方面,黄仁勋表示,“近年来,在认知能力和 .理解能力方面取得了巨大突破,这一领域的发展前景令人期待。我对人形机器人特别兴奋,因为它们最有可能适应我们为人类所构建的 .。与其他类型的机器人相比,训练人形机器人需要大量的数据。由于我们拥有相似的体型,通过演示和视频能力提供的大量训练数据将 .价值。因此,我们预计这一领域将取得显著的进步。”
黄仁勋还提出“数字人类”(digital humans)的概念,称“数字人类是我们的愿景”,可应用在客服、广告及电玩游戏等产业。
将加码AI PC市场?
在演讲中,黄仁勋还披露了英伟达进军AI PC的企图心。黄仁勋强调,英伟达在每一个 RTX GPU 中安装了张量核心处理器,因此也可以理解为,现在全球有 1 亿台基于 GeForce RTX 的AI PC,有超过200款搭载英伟达芯片的RTX AI PC,包括华硕、微星等PC品牌厂商都是合作伙伴。

在本次 Computex 2024展会上,英伟达将展示四款新的令人惊叹的笔记本电脑。黄仁勋表示,“它们都能够运行AI,运行由AI增强的应用程序。未来的PC 将成为一个AI,它将不断在后台帮助你、协助你。你所有的照片编辑、写作工具、你使用的一切工具都将由AI增强。你的PC还将托管带有数字人类的 AI 应用程序。因此,AI 将在不同的方式中表现出来并被用于PC中。PC 将成为非常重要的 AI 平台。”
值得注意的是,近期业内有传言称,英伟达(Nvidia)正准备推出一款将下一代 Arm Cortex CPU内核与其 Blackwell GPU内核相结合的芯片,主要面向Windows on Arm的AI PC设备领域。
考虑到目前英伟达在云端人工智能领域的统治地位,在生成式AI开始从云端进入到边缘端的趋势之下,英伟达希望凭借其强大的GPU能力以及近年来在自研Grace Arm CPU上积累的经验,以及期与PC制造商和服务器厂商多年来的深度合作,进入Arm Windows PC市场无疑一个市场机遇,特别是在PC市场正面临生成式AI PC所带来的换机潮的背景之下。



